Quick Answer (TL;DR)
This free PowerPoint template plans AI safety measures across five layers: Input Guardrails, Output Validation, Content Filtering, Red Teaming, and Incident Response. Each layer has initiative cards with severity ratings, affected AI systems, and measurable safety thresholds. Download the .pptx, map your AI systems to the safety layers, and build a defense-in-depth plan that prevents harmful outputs before they reach users. And handles them quickly when prevention fails.
What This Template Includes
- Cover slide. Product name, AI safety program scope, and the safety lead or ML platform team responsible.
- Instructions slide. How to map AI systems to safety layers, define severity thresholds, and design red teaming cadences. Remove before presenting.
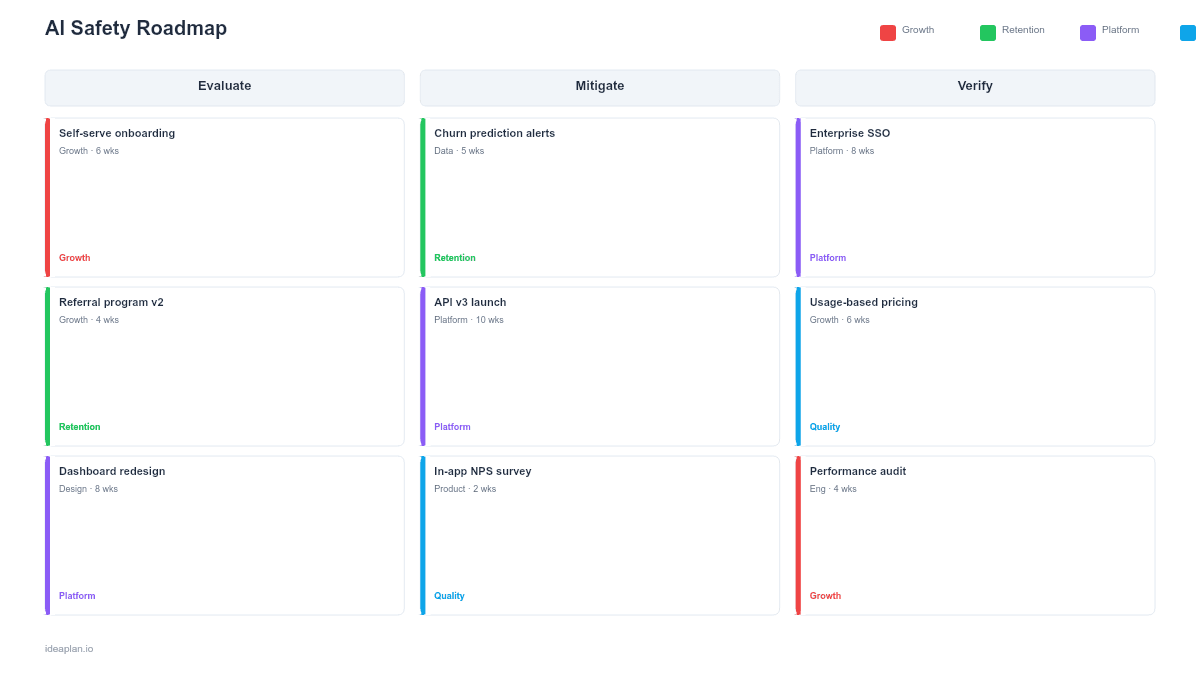
- Blank safety roadmap slide. Five horizontal layers (Input Guardrails, Output Validation, Content Filtering, Red Teaming, Incident Response) with initiative cards on a quarterly timeline. Each card shows the AI system, failure mode addressed, and safety threshold.
- Filled example slide. A consumer-facing AI product's safety roadmap showing prompt injection defenses, hallucination detection for a customer support bot, content toxicity filtering for a generative feature, quarterly red team exercises, and a tiered incident response plan.
Why AI Safety Needs a Layered Roadmap
AI safety is not a single feature you ship and forget. It is a stack of defenses, each catching failure modes that others miss. Input guardrails prevent malicious prompts from reaching the model. Output validation catches hallucinated facts and policy violations before they reach users. Content filtering blocks toxic or harmful generated content. Red teaming proactively discovers failure modes before adversaries do. Incident response handles the failures that slip through every other layer.
No single layer is sufficient. A model with strong input guardrails but no output validation will hallucinate confidently. A system with content filtering but no red teaming will be surprised by adversarial attacks it never tested for. The layered approach means each failure mode has multiple defenses, and a gap in one layer does not result in user harm.
For a structured approach to adversarial testing, the red teaming AI products guide covers methodology, team composition, and reporting.
Template Structure
Five Safety Layers
Rows represent the defense-in-depth stack:
- Input Guardrails. Prompt injection detection, input length limits, topic restriction filters, PII detection and redaction before model inference, and rate limiting per user. These prevent malicious or problematic inputs from reaching the model.
- Output Validation. Factual consistency checks against source documents, format validation (does the output match expected structure?), confidence scoring, and automated flagging of outputs below quality thresholds. The hallucination rate metric measures how well this layer performs.
- Content Filtering. Toxicity classifiers, personally identifiable information detection in outputs, profanity and hate speech filters, and brand safety rules. These catch harmful content that passes output validation.
- Red Teaming. Scheduled adversarial testing exercises targeting specific failure modes: jailbreak attempts, prompt injection, data extraction, bias exploitation, and edge case discovery. Findings feed back into the other four layers.
- Incident Response. Severity classification for AI safety incidents, escalation procedures, rollback playbooks, user communication templates, and post-incident review processes. This layer handles what happens when prevention fails.
Initiative Cards
Each card contains:
- Initiative name. Specific safety measure (e.g., "Deploy prompt injection classifier for chat API").
- Failure mode addressed. What goes wrong without this measure (e.g., "Users extract training data via adversarial prompts").
- Affected AI system. Which model or feature this protects.
- Safety threshold. Measurable target (e.g., "Block 99.5% of known injection patterns" or "Hallucination rate below 2%").
- Status. Planned, in development, deployed, or verified by red team.
Severity Matrix
A sidebar classifies each AI system's safety risk as critical, high, medium, or low based on potential user harm, data sensitivity, and system autonomy level. Critical systems (those making decisions without human review) need all five layers active before deployment.
How to Use This Template
1. Map AI systems to failure modes
For each AI system, enumerate the ways it could produce harmful outputs. A customer support chatbot might hallucinate refund policies, leak customer data, or generate toxic responses. A code generation tool might produce insecure code or bypass content policies. Be specific. "model might be wrong" is not actionable. "Model might hallucinate a return policy that costs $50K" is.
2. Assign safety layers to each failure mode
For each failure mode, identify which safety layers can prevent or mitigate it. Most failure modes need multiple layers. Hallucinated facts require output validation (primary defense) plus input guardrails (prevent prompts that tend to trigger hallucination) plus incident response (handle cases that slip through).
3. Prioritize by severity and likelihood
Use the AI risk assessment framework to score each failure mode by impact and probability. Deploy safety measures for critical failure modes first. A chatbot that could leak customer PII gets input guardrails and output filtering before a recommendation system that might suggest slightly irrelevant content.
4. Schedule red teaming exercises
Plan quarterly red team exercises focused on different attack surfaces. Q1 might focus on prompt injection for the chat API. Q2 might target data extraction from the search model. Rotate focus areas and include both internal testers and external red teamers for fresh perspectives.
5. Build and drill incident response
Document runbooks for each severity level. Practice them. A severity-1 AI safety incident (user harm, data exposure) should have a response time under one hour with clear escalation to engineering, legal, and communications. Track AI task success rate to catch degradation before it becomes an incident.
When to Use This Template
An AI safety roadmap is essential when:
- Generative AI features produce free-text, code, or media that users consume directly
- AI systems operate autonomously without human review of every output
- User trust is critical and a single harmful output could damage brand reputation
- Adversarial users are likely to probe AI features for exploits, jailbreaks, or data extraction
- Regulatory expectations include safety documentation and incident response procedures
For broader governance including policy and compliance infrastructure, the AI governance roadmap covers the full program. For ethics-specific work on bias and fairness, the AI ethics roadmap provides a dedicated template.
Featured in
This template is featured in AI and Machine Learning Roadmap Templates, a curated collection of roadmap templates for this use case.
Key Takeaways
- AI safety requires a layered defense: Input Guardrails, Output Validation, Content Filtering, Red Teaming, and Incident Response.
- No single safety layer is sufficient. Each catches failure modes the others miss.
- Prioritize safety measures by failure mode severity, starting with systems that can cause the most user harm.
- Quarterly red teaming exercises proactively discover vulnerabilities before adversaries or users do.
- Incident response plans must be documented, practiced, and tested before a severity-1 event occurs.
- Compatible with Google Slides, Keynote, and LibreOffice Impress. Upload the
.pptxto Google Drive to edit collaboratively in your browser.